Detailed Description of How DNA Controls Protein Synthesis

Photo by Libertas Academica
The control of protein synthesis by DNA has become a very remarkable scientific discovery that has changed the way we look at genetics and cellular organization. There have also been several solid evidences there to support these discoveries? In a post of this sort a review all the evidences in detail would be inexhaustive, but several pointers will be mentioned if only to give some indication of the kind of approach which has been made.
For example, the synthesis of RNA from free nucleotides in the presence of DNA has been carried out, and the relative proportions of the bases in the synthesized RNA were found to correspond to those of the DNA. Direct chemical analysis of cell components, together with the use of isotope tracers, has substantially proved the role of the ribosomes in protein synthesis. Transfer RNA have been identified and their structure has been worked out.
If this evidence seems rather negative the following is more positive. It has been shown that the position taken up by an amino acid in a polypeptide chain Is determine not by the amino acid but by the transfer RNA. The amino acid was then transformed by catalytic action into another amino acid. It was found that the latter became incorporated into the polypeptide as if it were the original one.
Thanks to the discovery of the necessary enzyme it is now possible to make synthetic RNA in the laboratory. Using synthetic RNA it has proved possible to induce the formation of unnatural polypeptides. For example, if a synthetic RNA consisting of nothing but uracil nucleotides (called poly-U) is added to a cell-free preparation of ribosomes, it directs the synthesis of a polypeptide chain consisting of nothing but the one amino acid phenylalanine. Similar experiments with other synthetic RNA, for example –A and poly-C, has made it possible to say exactly which triplets specify particular amino acids.
However, by far the most spectacular evidence of protein synthesis has come from experiments in which segment of DNA derived from one type of organism are introduced into another. This has been done mainly with micro-organisms, and in successful cases the foreign DNA has initiated the synthesis of messenger RNA which has been caused the formation of a particular protein1 quite apart from the support that this gives to our ideas of how DNA works, it opens up the possibility of all sorts of practical applications. For example, it might be possible to take the genes that code for the formation of interferon out of a human cell and introduce them into a harmless bacterium and its descendant’s might then manufacture interferon for human use. This kind of thing is usually labeled genetic engineering, and whilst it could bring tremendous benefit to mankind, it is also beset with great dangers. Can you think of some of the dangers? However, in the present context the important point is that genetic engineering provides strong evidence for DNA’s control of protein synthesis and a useful tool for studying how it works.
IS THE CODE OVERLAPPING OR NON-OVERLAPPING?
To understand the difference between an overlapping and non-overlapping code, consider the following hypothetical sequence of bases in a short length of messenger RNA:
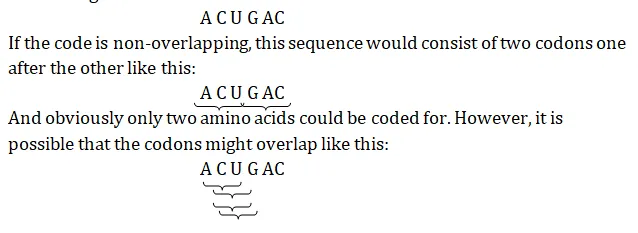
As can be seen, four amino acids would be coded for
The main advantage of an overlapping code is that it would permit a small number of bases to code for a relatively large number of amino acids, and this would enable an entire protein to be programmed by a relatively short length of DNA. On the other hand it would impose a constraint on the sequencing of the amino acids. In the above example if the first amino acid is coded by ACU, the second one will have to be coded by a triplet whose first two bases are CU, and the third one will have to start with UG, and so on. Obviously this will limit the flexibility of the code.
This limitation is one of the main arguments against the code being overlapping, but there is some empirical evidence too. We know that occasionally there is a mistake in the cod and this affects the sequence of amino acids in the resulting protein. This is called gene mutation. Now if the code is an overlapping one as depicted above, a mistake in a single base should affect no fewer than three amino acids in the protein. However, we know from studies on the inherited blood condition sickle-cell anemia that a mutation can involve just one amino acid. It therefore looks as if the code is non-overlapping.
TRANSCRIPTION AND TRANSLATION OF THE GENETIC CODE
The control of protein synthesis in a cell can be looked upon as a process in which a coded message is first transcribed and then translated. Specially, the coded message contained in DNA is transcribed into messenger RNA, and the coded message embodied in the RNA is then translated by the ribosomes into protein structure. The nucleotide triplets in the DNA and RNA can be regarded as code words. Knowing the amino acids that correspond to each code word it is possible to construct a genetic dictionary showing the relationship between the triplets in messenger RNA (i.e. the codons) and each amino acid.
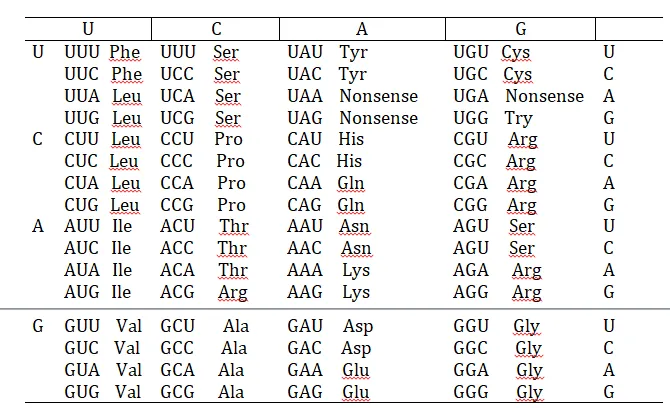
Code words for all 20 amino acids have now been worked out. It has been found that two or more triplets, differing from each other in one of their three nucleotides, may code for the same amino acid. It seems that generally only two of the three nucleotides are required to specify a particular amino acid. So the code contains more potential information than is actually used by the cell: to use the cybernetic term, the code is degenerate.
Some triplet do not code for any known amino acid: they are called nonsense triplets. But although they do not code for amino acids, they are important in ensuring that the construction of a polypeptide chain ends at affixed point. In other words, they tell the ribosomes where to stop reading the code.


